Data Ingest and Visualization - Matplotlib and Pandas
Overview
Teaching: 40 min
Exercises: 65 minQuestions
What tools can I use to create plots?
Why should I use Python to create plots?
Objectives
Import the pyplot toolbox to create figures in Python.
Use matplotlib to make adjustments to Pandas objects.
Putting it all together
Up to this point, we have walked through tasks that are often involved in handling and processing data using the workshop-ready cleaned files that we have provided. In this wrap-up exercise, we will perform many of the same tasks with real data sets. This lesson also covers data visualization.
As opposed to the previous ones, this lesson does not give step-by-step directions to each of the tasks. Use the lesson materials you’ve already gone through as well as the Python documentation to help you along.
Obtain data
There are many repositories online from which you can obtain data. We are
providing you with one data file to use with these exercises, but feel free to
use any data that is relevant to your research. The file
bouldercreek_09_2013.txt
contains stream discharge data, summarized at
15 minute intervals (in cubic feet per second) for a streamgage on Boulder
Creek at North 75th Street (USGS gage06730200) for 1-30 September 2013. If you’d
like to use this dataset, please download it and put it in your data directory.
Clean up your data and open it using Python and Pandas
To begin, import your data file into Python using Pandas. Did it fail? Your data file probably has a header that Pandas does not recognize as part of the data table. Remove this header, but do not simply delete it in a text editor! Use either a shell script or Python to do this - you wouldn’t want to do it by hand if you had many files to process.
If you are still having trouble importing the data as a table using Pandas, check the documentation. You can open the docstring in a Jupyter Notebook using a question mark. For example:
import pandas as pd
pd.read_csv?
Look through the function arguments to see if there is a default value that is
different from what your file requires (Hint: the problem is most likely the
delimiter or separator. Common delimiters are ',' for comma, ' ' for space,
and '\t' for tab).
Create a DataFrame that includes only the values of the data that are useful to you. In the streamgage file, those values might be the date, time, and discharge measurements. Convert any measurements in imperial units into SI units. You can also change the name of the columns in the DataFrame like this:
df = pd.DataFrame({'1stcolumn':[100,200], '2ndcolumn':[10,20]}) # this just creates a DataFrame for the example!
print('With the old column names:\n') # the \n makes a new line, so it's easier to see
print(df)
df.columns = ['FirstColumn', 'SecondColumn'] # rename the columns!
print('\n\nWith the new column names:\n')
print(df)
With the old column names:
1stcolumn 2ndcolumn
0 100 10
1 200 20
With the new column names:
FirstColumn SecondColumn
0 100 10
1 200 20
Matplotlib package
Matplotlib is a Python package that is widely used throughout the scientific Python community to create high-quality and publication-ready graphics. It supports a wide range of raster and vector graphics formats including PNG, PostScript, EPS, PDF and SVG.
Moreover, matplotlib is the actual engine behind the plotting capabilities of Pandas. For example, as we’ll see, we can call the .plot method on Pandas data objects - this actually uses the matplotlib package. There are also alternative plotting packages, e.g. PLotnine, which is also built upon Matplotlib.
First, import the pyplot toolbox:
import matplotlib.pyplot as plt
Now, let’s read data and plot it!
waves = pd.read_csv("data/waves.csv")
my_plot = waves.plot("Tpeak", "Wave Height", kind="scatter")
plt.show() # not necessary in Jupyter Notebooks
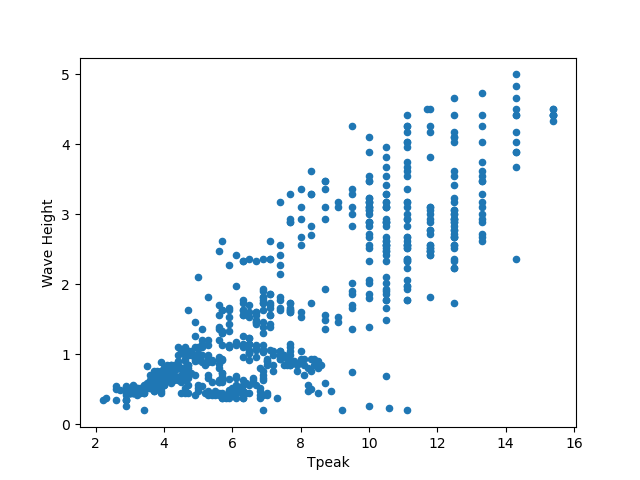
Tip
By default, matplotlib creates a figure in a separate window. When using Jupyter notebooks, we can make figures appear in-line within the notebook by executing:
%matplotlib inline
The returned object is a matplotlib object (check it yourself with type(my_plot)),
to which we may make further adjustments and refinements using other matplotlib methods.
Tip
Matplotlib itself can be overwhelming, so a useful strategy is to do as much as you easily can in a convenience layer, i.e. start creating the plot in Pandas, and then use matplotlib for the rest.
We will cover a few basic commands for creating and formatting plots with matplotlib in this lesson. A great resource for help creating and styling your figures is the matplotlib gallery (http://matplotlib.org/gallery.html), which includes plots in many different styles and the source codes that create them.
plt pyplot versus object-based matplotlib
Matplotlib integrates nicely with the NumPy package and can use NumPy arrays as input to the available plot functions. Consider the following example data, created with NumPy by drawing 1000 samples from a normal distribution with a mean value of 0 and a standard deviation of 0.1:
import numpy as np
sample_data = np.random.normal(0, 0.1, 1000)
To plot a histogram of our draws from the normal distribution, we can use the hist function directly:
plt.hist(sample_data)
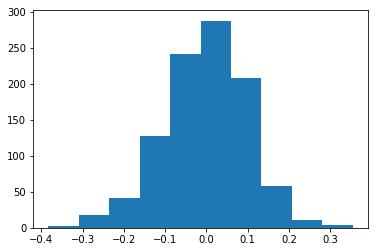
Tip: Cross-Platform Visualization of Figures
Jupyter Notebooks make many aspects of data analysis and visualization much simpler. This includes doing some of the labor of visualizing plots for you. But, not every one of your collaborators will be using a Jupyter Notebook. The
.show()command allows you to visualize plots when working at the command line, with a script, or at the IPython interpreter. In the previous example, addingplt.show()after the creation of the plot will enable your colleagues who aren’t using a Jupyter notebook to reproduce your work on their platform.
or create matplotlib figure and axis objects first and subsequently add a histogram with 30
data bins:
fig, ax = plt.subplots() # initiate an empty figure and axis matplotlib object
ax.hist(sample_data, 30)
Although the latter approach requires a little bit more code to create the same plot, the advantage is that it gives us full control over the plot and we can add new items such as labels, grid lines, title, and other visual elements. For example, we can add additional axes to the figure and customize their labels:
# prepare a matplotlib figure
fig, ax1 = plt.subplots()
ax1.hist(sample_data, 30)
# add labels
ax1.set_ylabel('density')
ax1.set_xlabel('value')
# define and sample beta distribution
a = 5
b = 10
beta_draws = np.random.beta(a, b)
# add additional axes to the figure to plot beta distribution
ax2 = fig.add_axes([0.125, 0.575, 0.3, 0.3]) # number coordinates correspond to left, bottom, width, height, respectively
ax2.hist(beta_draws)
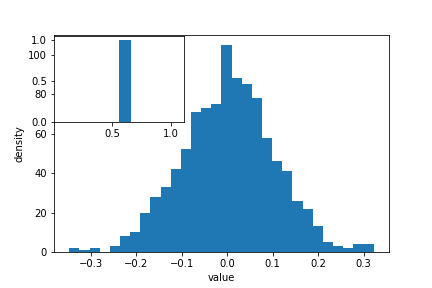
Challenge - Drawing from distributions
Have a look at
numpy.randomdocumentation. Choose a distribution you have no familiarity with, and try to sample from and visualize it.
Link matplotlib and Pandas
When we create a plot using pandas (or plotnine), it uses matplotlib to create those plots. The plots created in pandas or plotnine are matplotlib objects, which enables us to use some of the advanced plotting options available in the matplotlib library. Because the objects output by pandas and plotnine can be read by matplotlib, we have many more options than any one library can provide, offering a consistent environment to make publication-quality visualizations.
fig, ax1 = plt.subplots() # prepare a matplotlib figure
waves.plot("Tpeak", "Wave Height", kind="scatter", ax=ax1)
# Provide further adaptations with matplotlib:
ax1.set_xlabel("Tpeak (highest energy wave periodicity; seconds)")
ax1.tick_params(labelsize=16, pad=8)
ax1.set_ylabel("Significant Wave Height (metres)")
fig.suptitle('Scatter plot of Significant Wave Height versus Tpeak', fontsize=15)
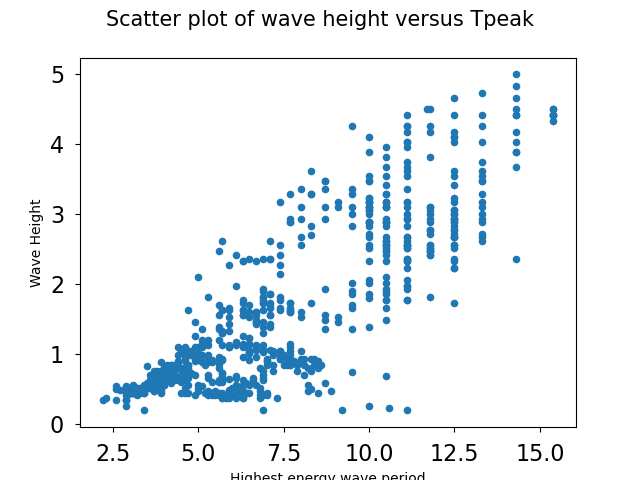
More complicated plotting
What about plotting after joining DataFrames? Let’s plot the water depths at each of the buoys
# water depth in the buoys dataframe is currently a string (it's suffixed by "m") so we need to fix that
def fix_depth_string(i, depth):
if type(depth) == str:
buoys_df["Depth"][i] = float((buoys_df["Depth"][i]).strip().rstrip("m"))
for i, depth in enumerate(buoys_df["Depth"]):
fix_depth_string(i, depth)
joined = pd.merge(left=waves_df, right=buoys_df, left_on='buoy_id', right_on='buoy_id')
plt.bar(joined["Name_x"].unique(), joined["Depth"].unique())
Notice that we have to use Name_x: where column names are duplicated between DataFrames, Pandas
appends _x to the column name that came from the “left”, and _y to the column name that came from
the “right”.
We can plot only the non-null values:
names = joined["Name_x"].unique()
depths = joined["Depth"].unique()
depths_df = pd.DataFrame({"depths":depths, "names":names})
depths_df = depths_df[~depths_df["depths"].isna()]
plt.bar(depths_df["names"], depths_df["depths"])
Note that the return type of .unique is a Numpy ndarray, even though the column were of type Series!
Challenge - subsetting data before plotting
Plot Tpeak vs Wave Height from the West Hebrides site. Can you add appropriate labels and a title, and Make both axes start at 0?
Answers
fig, ax1 = plt.subplots() waves[waves["buoy_id"] == 16].plot("Tpeak", "Wave Height", kind="scatter", ax=ax1) ax1.set_xlabel("Highest energy wave period") ax1.tick_params(labelsize=16, pad=8) ax1.set_xbound(0, waves[waves["buoy_id"] == 16].Tpeak.max()+1) ax1.set_ybound(0, waves[waves["buoy_id"] == 16]["Wave Height"].max()+1) fig.suptitle('Scatter plot of wave height versus Tpeak for West Hebrides', fontsize=15)
Challenge - grouping data before plotting
Can you group the waves data by buoy id, find only the maximum value for wave height for each buoy, and then plot Temperature vs Wave Height for these values. Is there more useful information you could add to this plot?
Answers
data = waves.groupby("buoy_id").max("Wave Height") x = data["Temperature"] y = data["Wave Height"] fig, plot = plt.subplots() # although we're not using the `fig` variable, subplots returns 2 objects plot.scatter(x, y) # notice a different way of creating a scatter plot for i in data.index: plot.annotate(i, (x[i], y[i]), xytext=(5, -5), textcoords="offset pixels") # annotate the point with the buoy index
Challenge - multiple datasets
Plot Wave Height vs Tpeak for both the West Hebrides and the South Pembrokeshore buoys. Change the marker style for one of the Series, and make sure that you include a legend
Answers
fig, ax = plt.subplots() wh = waves[waves["buoy_id"] == 16] pb = waves[waves["buoy_id"] == 11] ax.scatter(wh["Tpeak"], wh["Wave Height"]) ax.scatter(pb["Tpeak"], pb["Wave Height"], marker="*") ax.legend(["West Hebrides", "South Pembrokeshire"], loc="best")
Saving matplotlib figures
Once satisfied with the resulting plot, you can save the plot with the .savefig(*args) method from matplotlib:
fig.savefig("my_plot_name.png")
which will save the fig created using Pandas/matplotlib as a png file with the name my_plot_name
Tip: Saving figures in different formats
Matplotlib recognizes the extension used in the filename and supports (on most computers) png, pdf, ps, eps and svg formats.
Challenge - Saving figure to file
Check the documentation of the
savefigmethod and check how you can comply to journals requiring figures asAnswers
fig.savefig("my_plot_name.pdf", dpi=300)
Make other types of plots:
Matplotlib can make many other types of plots in much the same way that it makes two-dimensional line plots. Look through the examples in
http://matplotlib.org/users/screenshots.html and try a few of them (click on the
“Source code” link and copy and paste into a new cell in Jupyter Notebook or
save as a text file with a .py extension and run in the command line).
Challenge - Final Plot
Display your data using one or more plot types from the example gallery. Which ones to choose will depend on the content of your own data file. If you are using the streamgage file
bouldercreek_09_2013.txt, you could make a histogram of the number of days with a given mean discharge, use bar plots to display daily discharge statistics, or explore the different ways matplotlib can handle dates and times for figures.
Key Points
Matplotlib is the engine behind plotnine and Pandas plots.
The object-based nature of matplotlib plots enables their detailed customization after they have been created.
Export plots to a file using the
savefigmethod.